Open Source - Como distribuir parcialmente o código do seu sistema
Introdução
O objetivo desse artigo é descrever como se pode abrir parcialmente o código fonte de um sistema, e manter parte fechada. Esse tipo de estratégia é usada em larga escala por motivos diversos, onde uma empresa ou um profissional disponibiliza uma versão do seu sistema com funcionalidades gratuitas e mediante pagamente disponibiliza uma versão completa. Abrir o código fonte é um pouco mais além, porque todo mundo, e quando eu digo todo mundo, isso inclui o meu pai, minha mãe, o papa, você, os seus amigos e a torcida do Corinthians têm acesso ao código fonte do sistema que eu desenvolvi.No caso do código fonte do meu sistema, você pode copiar, alterar, redistribuir, contanto que mantenha sempre a referência à quem criou o sistema.
Será utilizado o sistema de versionamento de código fonte Git, e é necessário que você saiba usá-lo minimamente. Se você não sabe usar o Git, procure documentos na Internet e estude antes de ler esse documento. É necessário também saber usar o Github, repositório público que distribui códigos abertos.
Liberar totalmente o código fonte de um sistema é tarefa relativamente mais fácil do que abrir uma parte do sistema e manter uma parte sob o seu controle. Em sistemas parcialmente abertos você precisa planejar e controlar o que não vai ser distribuído, sob o risco de acabar divulgando informações que não deseja. Porém mesmo em um sistema totalmente aberto você precisa controlar alumas informações, como configurações locais de acesso a banco de dados, endereço de aplicações locais, senhas etc. Esse tutorial utiliza alguns comandos que são utilizados para controlar o que é enviado para os repositórios públicos do Github e que eu uso para controlar o código que estou abrindo e a parte que estou mantendo fechada.
Existem muitas razões para se abrir o código de um programa e manter uma parte fechada, como estratégias de evolução de um produto, prova de conceito, teste com a comunidade, criar produtos freemium, etc. Além de retornar para a comunidade o uso que se faz de software livre e sistemas open source. Eu particularmente venho usando há muito anos.
Separação de código aberto e fechado
Para cada tecnologia utilizada devem ser definidas estratégias específicas de separação de código.Para linguagens de programação orientada à objetos, pode se utilizar uma classe base e distribuí-la com o código aberto e usar a mesma classe no código fechado. O código fechado pode extender através da classe base, outras classes que forneçam atributos e métodos que não são distribuídos.
Linguagens de script, arquivos textos, templates HTML podem utilizar includes para extender as suas funcionalidades que não serão divulgadas, e utilizar a mesma estratégia de ter uma base comum que pode ser aberta.
Existem muitas maneiras de se fazer o que esse artigo descreve, algumas inclusive talvez sejam muito mais eficazes que a minha abordagem. Como eu não tive tempo de pesquisar, desenvolvi essa que tem me servido bem até agora.
Planejamento da abertura do código
Se você quer abrir o código do seu sistema mas pretende faze-lo parcialmente, é necessário um bom planejamento.Como nem sempre é possível planejar antes de iniciar a codificação, o trabalho passa a ser de análise sobre o código já existente, e as etapas abaixo devem ser seguidas:
- Definir a parte do código que vai ser aberta
- Isolar a parte do código que não vai ser aberta via include de arquivo, herança de classes etc
- Criar os repositórios de versionamento
Via de regra, os arquivos que não serão divulgados devem existir como na estrutrura do código que será divulgado em forma de arquivos dummy ou classes com método stub com retorno vazio, porque o código comum ao código aberto e ao código fechado fará a chamada dos arquivos, instanciará as classes, chamará os arquivos de qualquer maneira, portanto esses arquivos devem existir em ambos os casos mas fornecerão um retorno diferente para cada caso.
Repositórios
Em princípio, dois repositórios são suficientes para manter um código com duas versões, um para o código fechado e um para o código aberto, onde o código aberto é um subconjunto do código fechado. Os repositórios podem estar na própria máquina do desenvolvedor ou em um servidor local, ou ainda em um serviço remoto na nuvem, como o Github por exemplo.Por razões de segurança e facilidade de operação, eu considero que a estrutura mínima necessária para se manter uma código com duas versões, uma aberta e uma fechada, se baseia em três repositórios. Dois repositórios locais e um repositório remoto público.
Setup inicial
O setup inicial consiste em criar os repositórios do git, fazer o commit inicial e configurar os arquivos restritos, que não devem ser abertos.Criando os repositórios locais
Localmente são utilizados dois repositórios Git, um repositório com todo o código e outro apenas com o código que será distribuído livremente.A maneira mais pratica que eu encontrei para versionar dois códigos diferentes que utilizam uma base comum, foi inicializar dois repositórios Git no diretório do código fonte.
Outras maneiras para versionar os códigos seria utilizar um único repositório com branches ou ainda um único repositório com submodule.
Para utilizar dois repositórios Git:
- Entre no diretório do seu sistema e inicialize um repositório do git. Esse será o repositório original com todo o código.
$ git init
Por padrão, o Git cria um repositório oculto chamado .git. Renomeie (mova) esse repositório :
mv .git codigo_fechado.git - Repita as operações acima para criar um repositório para o código aberto:
$ git init
mv .git codigo_aberto.git
Você terá dois repositórios Git e deverá efetuar commit nos dois de maneira independente para manter os códigos aberto e fechado. Você verá como fazer isso à seguir.
O .gitignore e o Git hooks você também verá logo em seguida para que servem e como criá-los.
Configurar os arquivos restritos
Antes de configurar o repositório remoto no Github, vamos configurar as restrições para que você não distribua indevidamente os arquivos que você quer manter privados, restritos, fechados.Conforme descrito acima no ítem “Planejamento da abertura do código”, eu estou usando a abordagem de criar arquivos dummy, e/ou classes com métodos de retorno vazio para o código que não será aberto. Isso é para que eu possa usar uma base comum de código sem ter problemas de dependência, em decorrência de que o código aberto não receberá todo código fonte do código fechado.
Os arquivos dummy e as classes com retorno vazio preenchem a necessidade de compilação do código aberto mas não acrescentam as funcionalidades existentes no código fechado.
Existem algumas maneiras no Git para restringir acesso, através de commits, pushs e pulls de repositórios. Eu irei detalhar somente os dois processos que estou usando.
O primeiro deles é utilizar um arquivo, que controla restrições de atualizações, chamado .gitignore. O segundo é utilizar hooks do git, que são diretivas de processamento.
Para a minha necessidade seria possível controlar tudo com hooks, porém estou usando também as restrições do .gitignore. Futuramente se não for necessário, excluirei o uso do .gitignore.
https://help.github.com/articles/ignoring-files
O primeiro deles é utilizar um arquivo, que controla restrições de atualizações, chamado .gitignore. O segundo é utilizar hooks do git, que são diretivas de processamento.
Para a minha necessidade seria possível controlar tudo com hooks, porém estou usando também as restrições do .gitignore. Futuramente se não for necessário, excluirei o uso do .gitignore.
.gitignore
Utilize as informações da url abaixo para criar um arqivo .gitignore, para que o diretorio codigo_fechado.git não seja copiado para o repositorio do Github, que será criado no próximo item. Basicamente você só precisa criar um arquivo vazio na raiz do diretório do seu projeto e acrescentar arquivos e pastas que devem ser ignorados pelo Git.https://help.github.com/articles/ignoring-files
Isso é muito importante, se você não fizer isso, o seu diretório de código fechado vai ser publicado no Github, e o código será exposto.
O Git mantém uma lista padrão de arquivos e pastas para várias linguagens, que podem ser ignorados. Mas isso não é suficiente. Acrescente no mínimo a entrada codigo_fechado.git
ou *.git no seu arquivo .gitignore para não divulgar a pasta codigo_fechado.git.
O arquivo .gitignore DEVE ficar na raiz do diretório do projeto, no mesmo nível dos repositórios do Git, ou seja, FORA do repositório do Git e não dentro de um deles ou mesmo dentro dos dois.
Os hooks são scripts customizáveis que são executados de acordo com determinadas ações realizadas no processo de versionamento do Git. Para conhecer mais, acesse o link abaixo.
http://git-scm.com/book/pt-br
Os hooks são armazenados na pasta hooks do repositório onde você quer controlar a atualização dos arquivos. No meu caso, no repositório que distribui o código aberto.
Eu estou utilizando o hook pre-commit e associando-o a um script Perl que possui uma lista de controle (um array) onde eu adiciono o nome dos includes, arquivos de classes etc, que não quero que sejam distribuídos.
ou *.git no seu arquivo .gitignore para não divulgar a pasta codigo_fechado.git.
O arquivo .gitignore DEVE ficar na raiz do diretório do projeto, no mesmo nível dos repositórios do Git, ou seja, FORA do repositório do Git e não dentro de um deles ou mesmo dentro dos dois.
Hooks do Git
http://git-scm.com/book/pt-br
Os hooks são armazenados na pasta hooks do repositório onde você quer controlar a atualização dos arquivos. No meu caso, no repositório que distribui o código aberto.
Eu estou utilizando o hook pre-commit e associando-o a um script Perl que possui uma lista de controle (um array) onde eu adiciono o nome dos includes, arquivos de classes etc, que não quero que sejam distribuídos.
A estratégia que eu sigo é:
- Criação dos dos arquivos dummy que serão utilizados no código aberto
- Commit dos arquivos dummy no repositório de código aberto
- Alteração do hook pre-commit para incluir o nome desses arquivos na lista
Dessa maneira eu posso trabalhar com esses arquivos sem correr o risco de que eles sejam distribuídos indevidamente. Com uma ressalva, esse processo é todo manual, então se eu precisar alterar alguma coisa nos arquivos dummys, esse processo acima deverá ser repetido com muito cuidado para não distribuir arquivos fechados indevidamente.
Commitando
Como você tem dois repositórios Git no seu projeto, sempre que for fazer uma operação você vai ter que identificar em qual repositório você está atuando. Utilize a opção --git-dir.Por exemplo:
- git --git-dir=codigo_aberto.git add test.txt
- git --git-dir=codigo_aberto.git commit -m "Test"
- git --git-dir=codigo_aberto.git reset .
Criando o repositório para distribuição do código
Para distribuir o código e torná-lo aberto, vamos usar o repositório Github.
Se você não tem uma conta crie em https://github.com/
Os passos abaixo são uma reprodução do tutorial do próprio Github.
https://help.github.com/articles/duplicating-a-repository

Os passos abaixo são uma reprodução do tutorial do próprio Github.
https://help.github.com/articles/duplicating-a-repository
- Crie um repositório vazio diretamente no Github. Este repositório será utilizado para distribuir e tornar publico o seu código.
https://github.com// - No servidor local, ou na máquina de desenvolvimento, entre no diretório do projeto e execute o comando abaixo.
Esse comando faz um mapeamento e define que o repositório remoto do Github será atualizado à partir do conteúdo desse repositório local
$ git --git-dir=codigo_aberto.git remote add origin https://github.com// - Os comandos abaixo utilizam o mapeamento efetuado no ítem acima e atualizam o repositório remoto no Github. Você pode incluir esses comandos no cron e deixar que o Github seja atualizado automaticamente.
$ git --git-dir=codigo_aberto.git fetch -p origin
$ git --git-dir=codigo_aberto.git push --mirror
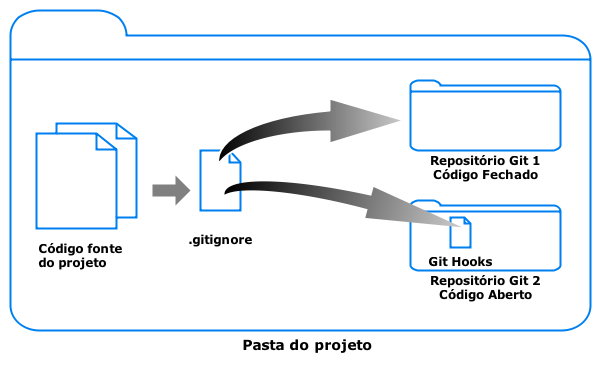
Representação dos repositórios de código
A figura abaixo representa os três repositórios de código, uma estrutura macro dos ambientes e o processo de atualização de cada ambiente.Comandos úteis
- Lista os commitsgit --git-dir=codigo_aberto.git log
- Adiciona as últimas alterações
git --git-dir=codigo_aberto.git add -u - Reseta o stagegit --git-dir=codigo_aberto.git reset
- Exclui o último commitgit --git-dir=codigo_aberto.git reset --soft HEAD^
- Exclui arquivos mapeados quando quiser excluir dos commits.
Se não excluir, arquivos que estão nos hooks vão dar pau e não deixar commitar.git --git-dir=codigo_aberto.git rm --cached nome_do_arquivo1 nome_do_arquivo2 - Assume que arquivo não foi alterado.
Serve para manter versões dummy no repositório remoto e alterar o repositório local
git --git-dir=codigo_aberto.git update-index --no-assume-unchanged - Para reverter o acima
git --git-dir=codigo_aberto.git update-index --assume-unchanged - Para recarregar à partir de uma "clonada"
git --git-dir=codigo_aberto.git fetch
git --git-dir=codigo_aberto.git reset --hard origin/master

