Django middleware - Crawler detection
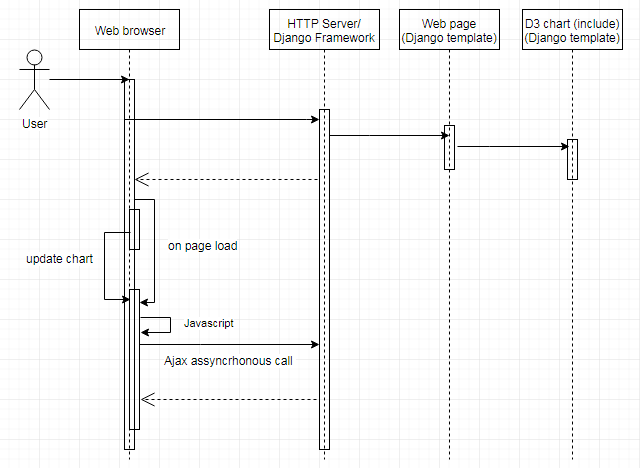
Sometimes you have to detect search engine crawling activity on your system, to handle the workflow for this type of request. On our website, there is a high crawling activity, because BV FAPESP (https://bv.fapesp.br) provides useful information abour reaserch for science, technology and academy in Sao Paulo state of Brazil. Recently, I deployed a feature on our system to allow people to store their queries and filters they do on our website. This is an open feature for everybody who navigates on our system. It is based on the HTTP session of the brower, which is stored on Python/Django server-side. When we were tunning Django session table in the database, we found out that there were a lot of sessions created by crawling activities. To take control of the session creation, I wrote the middleware that follows. The list of crawlers, I get from ngix logs, on a very small timeframe, so maybe there are some more search engines that are not listed. The use-case presented, ...